Let’s build a Perceptron in Python
Neural networks can be daunting when you don’t know much about them, especially when the internet is full of videos showing enormous and complex ones. The goal of this article is to introduce anyone (even the most complete beginner) to one of the building blocs of neural networks; The Perceptron (to be more precise, single layer Perceptrons). We will write a functioning one in python and hopefully you will gain some intuition on how they work. The article is divided into 2 parts, first we’ll investigate the different components of a Perceptron and how they work. Only once this is done we will get into coding one (Note that while the first part can be understood with no prior knowledge, for the second part I expect you to be somewhat familiar with python)
How a Perceptron works:

I believe explaining each element of the diagram above is a good way to get a first mental image of what a Perceptron is, but first let me phrase the problem it is going to solve:
We want to separate (x, y) points into 2 categories: those above a certain line and those below
Put simply, we are going to give our Perceptron a point (more precisely, its coordinates) and ask it the question: “Is this point above or below the line”, the line I’m talking about is one that we will have chosen beforehand, the one we will train our Perceptron on (Interesting terms coming up).
You may think that this is kind of a lame problem to solve… And I would agree with you, it doesn’t sound interesting and it could be solved really easily (and perfectly) using simple math… A single layer Perceptron is quite limited, in fact they are only able to solve problems similar to this one, but the goal here is not to solve any kind of fancy problem, it is to understand how the Perceptron is going to solve this simple problem.
Okay, now that we know what our goal is, let’s take a look at this Perceptron diagram, what do all these letters mean. Let’s first take a look at the X’s, what are they and why are they here. The X_0 is a special one (as you may have noted from the “=1” next to it) so please don’t pay attention to it right now, it will make an enormous amount of sense when I get to it. The other X’s represent the input. If we want to ask our Perceptron whether a point is above or below the line we have chosen, it must know about the point, this is where we give this information. You may have guessed it, in our case we will only need a X_1 and a X_2 as our input (point) can be represented with only its y and its x coordinate.
Trending AI Articles:
1. AI, Machine Learning, & Deep Learning Explained in 5 Minutes
2. How To Choose Between Angular And React For Your Next Project
Great! We know what the X’s mean (be patient for X_0 😉), then what are the W’s linking them to the weird green circle. They are the weights, they represent how important one of the input is (You could phrase it as “How much weight this part of the input has in the decision making process”). This is where the whole learning process happens, basically we will tweak these until we are satisfied with the results they yield, but I am getting ahead of myself here, this is for later.
Now to the weird green circle, allow me to call it the processor (I don’t know if there is an official name for it but weird green circle is not going to cut it). The fact that there are 2 different symbols in there already hints at there being 2 different processes. The first part (Sigma) refers to the weighted sum of the inputs, meaning the processor will calculate an internal value that is the sum of each input multiplied by its corresponding weight. This is represented by the following, not-yet-too-awful, formula:
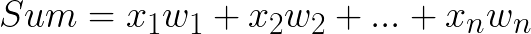
Before getting to the second part, this is where X_0 makes its great appearance. There is no better way to explain it to you than to show you its reason to be: What would happen if all inputs where to be equal to 0? Exactly, the sum would be 0. But 0 is such a special case, we don’t want it to be forced on the Perceptron by the input, we want weights to be able to change the inputs required to produce 0. This is why X_0 (and W_0!) are introduced, they form what we call the bias, a value that is completely independent from the input and that the processor will add to the weighted sum.
The second part of the processor (Phi) refers to the formatting part. As you can see from the formula above, the sum calculated by the processor can have any real value (depending on the input and the weights). But that may not be what we want, take our problem for example, we want to know whether a point is above or below a line, that means we expect only 2 different numbers in the output (we’ll use 1 and -1) not a whole range of number between minus infinity and infinity. That is why for our formatting we will use the sign function (giving -1 when a number is below 0 and 1 when a number is greater or equal to 0). After this formatting process, you finally get …. the output! (Yay I guess)
Alright that’s enough theory, I haven’t talked in length about how the Perceptron is going to learn but I feel like this is something that is easier to understand while writing the code so bear with me. Anyways, you and I just want to get to building this thing, let’s get coding.
Coding a Perceptron:
Finally getting down to the real thing, going forward I suppose you have a python file opened in your favorite IDE. We’ll start by creating the Perceptron class, in our case we will only need 2 inputs but we will create the class with a variable amount of inputs in case you want to toy around with the code later. In the constructor we will also initialize the bias and the weights (there is a lot of talk about how to initialize those but here we are working on such a simple problem that initializing them randomly will do the trick). After all this comes the following code
Why those random numbers you may ask, well I don’t know, choose whatever you want it shouldn’t matter if the numbers aren’t completely ridiculous. Next we want to implement the actual “thinking” process (don’t take it too philosophically) that is the 2 different things happening in the processor. Well, because we know what the processor does, we just have to lay the code down. Please note that the code below does not follow the actual architecture of the program, the normalizeValue function is outside the Perceptron class while the processInput function is inside of it.
Well well well, that’s great and all, we can get the Perceptron’s output for a certain input but this output doesn’t mean anything as it comes from a computation based on completely random values. In fact right now we have the (base for the) Perceptron but we don’t even have the problem going with it. Let’s jump out of the Perceptron class for a moment to build a few things we’ll need for the training process. This is where the magic happens, thanks to the following bits of code that we will add, the Perceptron will be able to, on its own, go from -completely wrong- to -almost always right-. We first need a function describing the line that we will compare our points to, and then we need a function creating a training set for our Perceptron (that is a bunch of random points and the outputs that the Perceptron should yield when given these points’ coordinates)
This implementation is surely not the only valid one, please do not hesitate to work out your own. That said you should pay attention to one thing: make sure that your points and your line equation make sense. Here I generate points in a 20 by 20 grid centered around 0, imagine what would happen if I set my line equation to 16x+50. Indeed, all the points would be far below the line. Then our training set could be considered garbage because it would not be representative.
Then comes the magic part, the training of the Perceptron, let me give you the code first, then I will explain it (note, both the following functions are inside the Perceptron class):
Don’t worry if you are currently raising an eyebrow, I admit this needs some explaining. To understand the reason to be of this code, let’s think about it more generally, you have an input coming in and you know the output the Perceptron should give, then you evaluate the value actually returned by your Perceptron, the difference between the expected value and the actual value is called the error. The goal of the training process is to minimize the error for any point. If the error is not zero, that means we can tweak something in the Perceptron to make it a bit better, but there are only so many things in there we can tweak: the weights and the bias. But then, how should we tweak them?
The first thing to realize is that if the error is really large (the Perceptron is completely wrong) then the different values should change quite drastically, on the other hand if the error is really small (the Perceptron was really close to getting the answer right) then we should barely change them. So it only seems natural that the amount by which we will change the bias and the weights is proportional to the error.
But that’s not all, suppose for this training input, one of the input value was really small, then it and its corresponding weight played a minor role in the Perceptron’s result (and the error), on the other hand if one of the input was really large, then it played a big role in the Perceptron’s result (and the error). So the amount by which the weights and the bias are changed should also be proportional to the input value (for the corresponding weight). But then, what about the bias you may ask, it has no input value, does it? Well let me send you back to the beginning of the article, to the diagram representing a Perceptron, remember that the bias is just a weight to which we associate a constant input value of one.
The last thing I should talk about is this learning rate, it is here to avoid overshooting; if we were to change all the values so much that we just made things worse it wouldn’t do us any good. Usually, values for the learning rate are around 0.1 (I encourage you, once you get everything working, to try out different values for the learning rate, from 10 to 0.00001, what changes?).
Now that we are done with the Perceptron’s code, all we have left to do is to write the code that will create and run our Perceptron, not much to say here. I can only encourage you to do that part on your own, I’ll give you my implementation in case you are stuck. One thing I highly recommend if you are going on your own is to write something that allows you to judge how well the Perceptron is performing.
Well, that’s it, looks like we are done! I hope you got every part of the code stitched correctly, if not you can always refer to the full code on GitHub.
Allow me to thank you for bearing with me for so long, I hope you gained something valuable from reading this article. Please keep in mind that I am no expert on the subject nor am I a renowned teacher (far from both), if you have any question, comment, or review, please do not hesitate to share it (Twitter is a pretty good place if you just want to chat)
Considering you’ve made it this far, I would guess you are somewhat interested in the world of artificial intelligence/neural networks. You will find below some complementary exercises in case you’d like to test your understanding as well as some additional resources to provide you with some guidance.
Complementary Exercises:
- (Easy) Can you modify the code so that you change the problem from “Is this point above or below that line” to “Is that point above or below that plane”
- (Easy) Go ahead and toy around with the learning rate, can you predict what happens if you set it to 10? to 0.00001? Can you change the code so it starts at 0.5 and gradually reduces to 0?
- (Medium) Add a function to the Perceptron class to keep track of the value for the weights and the bias as they are being changed through the training.
- (Hard) It is actually possible to deduce the line that the Perceptron is guessing from the weights and the bias, can you find the formula? (Hint: write down the weighted sum’s formula)
Additional Resources:
- The Coding Train’s playlist on neural networks. He works in processing (Java) and JavaScript, but don’t let that stop you, the guy explains extremely well and takes it from the beginning (The Perceptron).
- 3Blue1Brown’s short series on neural networks. You won’t see any bit of code here, but if you first want to build an intuition for neural networks, this is the place to go.
- If you prefer written articles, towardsdatascience has some interesting ones, it’s all about finding the one for your level. Here are a few ones that are also introductory but skip more detail to go faster. One by Matthew Stewart, one by David Fumo and one by Victor Zhou
Thanks for reading.
Don’t forget to give us your 👏 !




