My Week in AI: Part 3
Welcome to My Week in AI! Each week this blog will have the following parts:
- What I have done this week in AI
- An overview of an exciting and emerging piece of AI research
Progress Report
Building skills in big data and discovering dashboarding
This week I learned about big data engineering by starting the ‘Advance Your Skills as an Apache Spark Specialist’ learning pathway on LinkedIn Learning. I am somewhat familiar with Spark and Hadoop, but I wanted to learn more, and this seemed like a good way to gain those skills.
I also read a lot this week about data visualization in Python. I came across a powerful dashboarding library called Altair, which allows you to build very aesthetic dashboards and visualizations. It only requires Python knowledge and is based on visual grammar, so it is fairly intuitive. This is definitely a library I am going to add to my toolbox and explore further.
Applying for Etsy Fellowship
I spent another large part of my week brainstorming, researching, and writing a proposal for Etsy’s Summer of Vision Fellowship program. The assignment was to develop a machine learning project based on the question, “How might we use visual cues to improve buyers’ shopping experience on Etsy?” This prompted me to read a lot about recommendation systems, computer vision in e-commerce, and the use of computer vision and NLP in concert for such applications.
Trending AI Articles:
1. Natural Language Generation:
The Commercial State of the Art in 20202. This Entire Article Was Written by Open AI’s GPT2
3. Learning To Classify Images Without Labels
4. Becoming a Data Scientist, Data Analyst, Financial Analyst and Research Analyst
Emerging Research
Visiolinguistic Attention Learning
As part of my research for the Etsy Fellowship application, I came across a paper by Chen, Gong and Bazzani called ‘Image Search with Text Feedback by Visiolinguistic Attention Learning’ that will be presented at the upcoming CVPR 2020 conference¹. The paper discusses a new framework that these researchers developed: given a reference image and text feedback such as ‘same but in red’ or ‘without buckle,’ images may be retrieved that resemble the reference image but with the desired modification as described by the text. A potential application for this would be as a search feature on an e-commerce site.
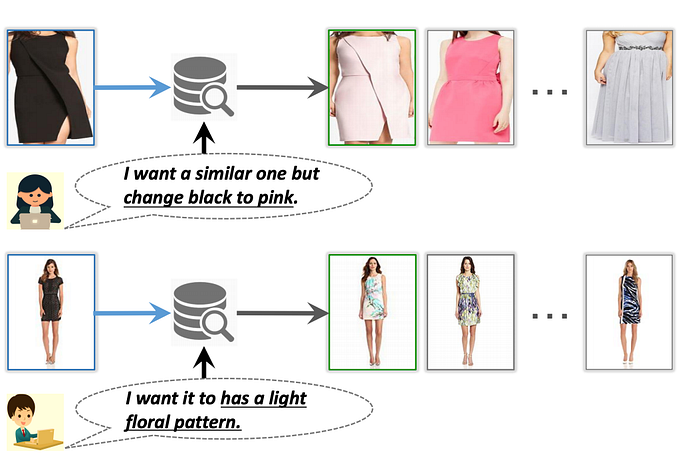
This task involves learning an amalgamated representation that captures visual and textual information from the inputs. In order to do this, the authors presented the Visiolinguistic Attention Learning (VAL) framework, which is made up of three parts: an image encoder, a text encoder, and multiple composite transformers that modify visual feature maps based on language information. The image encoder was made up of a typical CNN with feature maps being extracted from several different layers, and the text encoder was made up of an LSTM followed by max pooling and linear projection layers.
To me, the most fascinating part of this research is in the visiolinguistic representation using the composite transformers. The visual and language features are fused and then passed through a two-stream module that learns attentional transformation and preservation. First, the self-attention stream learns non-local correlations in the fused features and generates an attention mask that highlights spatial long-range interdependencies. In parallel, a joint-attention stream works to retain the visual features of the reference image. The outputs of these two streams are combined to create a set of composite features.

In terms of training, hierarchical matching is utilized. The primary objective function relates to visual-visual matching so as to ensure that the composite features are very similar to the target features. The secondary objective function relates to visual-semantic matching, which is useful when images have accompanying text such as descriptions or tags.
In my opinion, the exciting applications of this research are for online shopping. If you see a pair of shoes that you like but would prefer them in a different color, you’d just have to type “I like these, but in blue” and the website will attempt to find for you a blue version of the original pair of shoes. This combination of semantic and visual features is not something I have come across much (probably because it is a very difficult task!).
Join me next week for more updates on my progress and a look at some cutting-edge research in the field of time series forecasting. Thanks for reading and I appreciate any comments/feedback/questions.
An update on my blog post from last week which you can find here; IBM announced on June 8th that they will cease all work on facial recognition due to fears that their products could be used for racial-profiling and perpetuating biases.
Update June 11th: Amazon will not allow usage of it’s facial recognition software by police for at least the next year.
References
[1] Y. Chen, S. Gong, and L. Bazzani. “Image Search with Text Feedback by Visiolinguistic Attention Learning,” IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020.
Don’t forget to give us your 👏 !




